









A Mukhopadhyay
Technical Consultant, CALIBNET
Department of Scientific & Industrial Research
Regional Computer Centre, Jadavpur University Campus, Calcutta 700-032. INDIA
Internet: director[at]clib0[dot]ernet[dot]in
Abstract
Describes the basic features of the library management software package SANJUKTA, created to support the requirements of the central databases of Calcutta Library Network called CALIBNET. It comprises storage and retrieval modules borrowed from MOD+. The modules have been revised and implemented in FoxPlus platform under Unix environment.
KEYWORDS: Library management software package; Software package; SANJUKTA
INTRODUCTION
SANJUKTA, a bibliographic information storage and retrieval software, came into being in 1998 to support the requirements of the central databases of CALIBNET, a Government of India project, sponsored by the National Information System for Science & Technology (NISSAT). SANJUKTA has made it possible for CALIBNET to provide its user community with online access to its databases through modem connectivity, before its going to the Net.
SANJUKTA is a special version of MOD+, a library management software, developed in 1993. The design of MOD+ was evolved through a process, initiated in 1989, of experimenting with the bibliographic data model using dBase3+ [1]. SANJUKTA, on the other hand, consists of the storage and retrieval modules borrowed from MOD+. The modules were revised and implemented in FoxPlus platform under Unix environment.
SOFTWARE FEATURES
SANJUKTA supports storage, search & retrieval, and dissemination of bibliographic information. Since the centralized databases maintained in CALIBNET comprise records transferred from external sources, the software requires the capability of exporting records generated on varied systems in dissimilar bibliographic formats. SANJUKTA, backed by the conversion package, PARAPAR, is empowered to interchange USMARC, UNIMARC and CCF records as and when needed. It provides the end-users at remote stations with a user-friendly facility to search the central databases employing Boolean operators and techniques like truncation and field restriction. The users can supply their search terms, or preview the available search terms in alphabetical order in a window for cursor-selection. The search-hits may be displayed in variant formats, the default being AACR2. The other choices are : the labeled representation commonly used in OPAC, UNIMARC, or USMARC.
THE MODEL
The database can be viewed as a network of interconnected records, allocated in multiple files, each holding records of one type. Two classes of record types are employed: Master Records and Data Records.
Master Records
A Master record consists of an array of pointers to related data records. A database key, or the system- provided ID, of a Master Record serves as the control key used for accessing the record directly.
Data Records
The Data records have no primary keys, and can only be accessed through association of a Master record. There are different types of Data records each having its own format. Data record types may be divided into two subclasses: single entry records and multiple entry records. Single entry records consist of one or more fixed-length data fields designed to hold one fixed-length single-occurrence bibliographic element. Multiple entry records consist of a single fixed-length data field designed to hold a segment of one variable-length and/or multi-occurrence bibliographic element.
The model represents parent-child relationship between the master record and its data records. It supports one-to-many relationships. Many-to-many relationships can be achieved by implementing multiple instances of one-to-many relationships. The Master record is always a parent and never a child. It may have one or more child records, while a child record may have one or more Master records. The characteristics of a child record distinguish SANJUKTA from a hierarchical model that does not support more than one parent for a child record. Linkage paths are established through a set of pointers resident in the Master record.
THE DATABASE
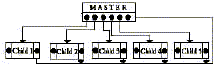
SANJUKTA database includes six record-types _ one Master record and five different data record-types. Each of the record-types has unique format. Fig. 1 represents the basic model using a box for Master records and a circle for a data record, a straight line for a linkage path, and a big dot indicating many instances of a child record.
Physical Database Structure
The model I used to develop the physical design of the database was translated into a physical database structure to support the actual operational requirements of the system. Fig. 2 illustrates the arrangement of the SANJUKTA files and its inter-file connectivity through pointers.
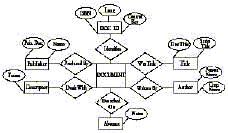
For better understanding of the data semantics of SANJUKTA an object-oriented representation is provided in Fig. 3. It has evolved by transforming the record-types into object-sets, and indicates their key attributes as well as the relationships existing between object sets.
Core Files
To provide fast access, the database keys are employed as inter-file pointers. It demanded, in return, greater programming efforts to deal with retention constraints, particularly for providing the data editing facilities. The Master record, in file File0, holds an array of pointers to the related records in File1, File2, File3, File4 and File5. On the other hand, each of those subordinate files has the database-key of their Master record as the master pointer. The master pointer provides access to the Master record in the file - File0. It is only through the instrumentality of Master record that an inter-file access is implemented.
Table 1: File Structure
| Files | File Content | Inter-file Connectivity |
| File0 | Record Type: Master | Array of pointers directed to subordinate files |
| File1 | Record Type: Title | Pointers directed to Master |
| File2 | Record Type: Author | Pointers directed to Master |
| File3 | Record Type: Pub-Ref | Pointers directed to Master |
| File4 | Record Type: Notes | Pointers directed to Master |
| File5 | Record Type: Descriptor | Pointers directed to Master |
Auxiliary Files
Besides the core files, the application software works with a number of auxiliary files. Two of them, namely, Unidoc and Docbase, contain unitary records comprising all related data elements of particular documents. File Unidoc is an extension of File family, especially introduced to meet library housekeeping needs. It stores the volume-copy-specific data relative to Master file records. Unidoc is directly connected with the Master file - File0, through master pointers. It is, however, not a member of the core file family as it does not require the Master file intervention, but provides access to the Master files through master pointers. Docbase, on the other hand, is a totally independent file with no pointers to allow interaction with the core files. It may be called a parallel file since it can hold, as and when needed, all the data stored in the core files. It serves as the gateway for interchanging records with external ISO 2709 databases, and also with the internal core files. The rest of the auxiliary files contain processing data not related to any specific document. Examples of such files are stop-word file, authority files and circulation file. All these are accessible only through key-field values provided by the user.
Access File
The database search is implemented by means of a consolidated inverted file. The file consists of searchable keys extracted from the records stored in various core files, along with codes for the source record-types and master pointers. This inverted file serves as the primary search instrument for end users.
Record Structure
Each of the core files has unique structure to suit the special requirements of the data elements it stores. The structures of Master record-type and the Pub-Ref record-type are relatively simple. The structures of some record types are complex, for example, the record-types Title and Author.
The complexity arises out of the contingencies in respect to data length and times of occurrence. The field designated for Document Title also accommodates Series Title with a Series Code in a related field for differentiation. For example, in a Title record-type, the software addresses those eventualities by providing a modular structure that facilitates adding up modules to accommodate data elements of indeterminate field length and/or number of occurrences. The sequence of modular records is maintained with the help of a pointer. Another pointer controls occurrences of a data element. The master pointer, occurrence pointer and the module pointer, collectively serve as an instrument to access data elements of a particular document. Related data elements extracted from the set of core-files comprise a logical record.
Sub-Field Delimiters
Some of the record-types' sub-fields are utilized to provide additional information when needed. Certain user-provided punctuation marks, prescribed in ISBD/AACR2, serve as sub-field delimiters. In record-type Title, a colon separates a subtitle from title proper and a slash separates statement of responsibility and title. In record-type Author, a comma separates the tail-end of a personal or corporate name from its key part, and an opening square bracket separates a personal name and the name of an affiliated body.
Format Integration
The software supports integrated bibliographic information and maintains records of documents of print and non-print material types belonging to different bibliographic levels. The Master record provides GMD and bibliographic level codes to control input/output formats, particularly in respect of publication specific data. The record type Pub-Ref holds data of those kinds. Pub-Ref is, in fact, a combination of logically distinguished publishing data elements, namely, imprint, physical description and reference to article source. All these are variable data and often appear in records selectively, depending on the material type and bibliographic level.
CONCLUSION
The database design provides opportunities for further research into the network approach. The implementation of pointers is no doubt a hazardous task; but once achieved, the pointers lend a system much greater control and speed than what can be achieved with relational approach. However, in recent times, the access-speed and memory-space have improved stupendously in course of unprecedented advancement in computer technology. It is, however, all important for us to see that the data model we use must let our application software negotiate with every data type to produce precise and unaffected information.
REFERENCE
1. Mukhopadhyay A. Experimental design of a bibliographic database with variable structure and field-length for dBase 3+ application. IASLIC Bulletin 1991; 36( 2) : 81-91.
Contact: A.C. Mitra, Director, CALIBNET, Regional Computer Centre, Jadavpur University Campus, Calcutta- 700-032. E-mail: director[at]clib0[dot]ernet[dot]in for more information.
* An Information Storage & Retrieval Software developed using Network Model in CALIBNET, Kolkata
Information Today & Tomorrow, Vol. 20, No. 1, March 2001, p.3-p.5
http://itt.nissat.tripod.com/itt0101/sanjukta.htm









